

3rd party integrations can be tedious because of lack of visibility into behind-the-scenes processes. Here’s how to use 3rd-party integrations’ observability to identify errors fast, making development more efficient.
3rd party integrations are inevitable in development. Some functionality is outsourced as there is no need to develop something in-house that’s already working, while some integrations are performed to connect with the customer’s ecosystem to help them get their job done better.
Whatever the reason you’re integrating with 3rd parties, the process isn’t always a smooth one, at least on the first try as we developers often encounter faulty flows. Unless we catch and log the error received, we have to debug our code, breakpoint on the interaction itself, and start examining its result if we want to understand the root cause. This can be more or less tedious, depending on the complexity of the implemented flow – and quite frustrating, depending on the maturity and stability of the third-party app you’re integrating with.
3rd party integrations observability helps to streamline this process, providing end-to-end visibility into applicative flows as early as in your local development environment, so you can easily pinpoint errors. Below, I take a look at a real-world example of how I used Helios to simplify an integration with a common third-party tool (Hubspot) and save significant time while building that feature. You may want to start with better understanding our approach to developer-first observability.
Why 3rd party integration is complex
When integrating with third parties, various services can be involved and their requirements are driven by different reasons, for example:
- Integrations with products such as Hubspot, Jira, and Shopify which are part of the product offering to customers
- Integrations which are used for internal purposes like analytics and reporting tools (Segment, Tableau, etc.)
- Integrations that are directly based on dev team needs such as databases (which can be managed services like s3, DynamoDB, etc), monitoring and logging tools, etc.
The tricky thing about these integrations, as opposed to internally developed services, is that the integration process relies on the “black boxes” providing proper feedback on our implementation and usage (I say black boxes because we often have no idea or access to the implementation and no way of changing it, so we must interact with it knowing only the API). More often than not, the documentation is not as elaborate and explicit as we’d like it to be, and the development process requires a bit of trial and error when things don’t work as expected (which usually they don’t.)
Example: Delivering a feature that included sending an email to users via Hubspot
Recently, we added the ability to share traces via email. I was tasked with building this feature and decided to leverage our existing Hubspot integration when I ran into an issue.
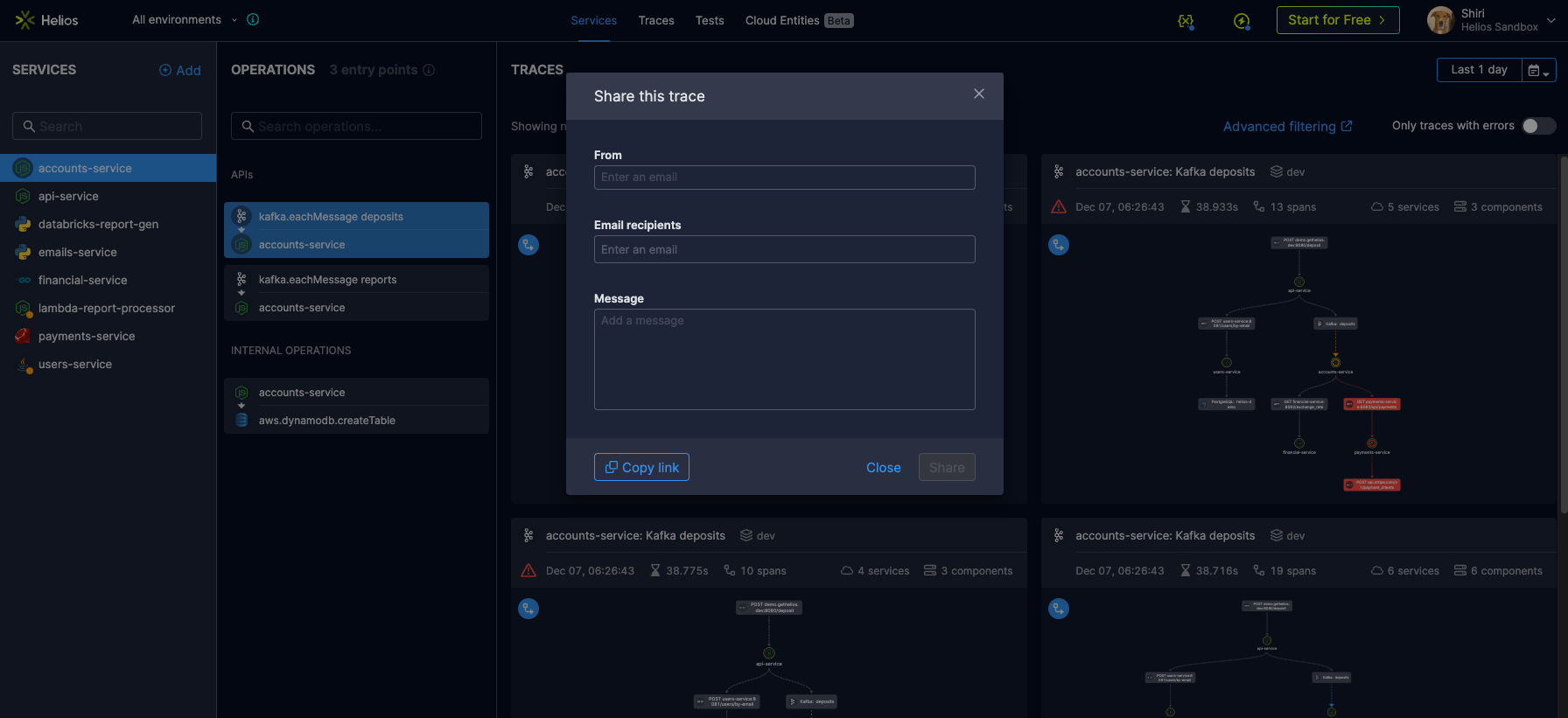
I followed the API’s documentation and added the required code to our service. Then it was time to test it locally. I started mimicking the flow that should trigger the email (which was quite complex as it contained several applicative steps) and expected to receive the email. Since the email was an asynchronous side effect of the said flow, no faulty indication was visible in the application – yet no email was received. A quick look at the run console (reminder: I was testing it locally) showed that an error has occurred and was logged to the console, though the log did not contain any useful details.
[dev:server] error: Failed triggering hubspot email 9xxxxxxxxx4; response status is 400. Failed
triggering hubspot email 9xxxxxxxxx4; response status is 400.
{"go_to_helios":"https://app.gethelios.dev?actionTraceId=30c4caf510e99104bf8e411f8578a454&spanId=f80f3d4cb20e1a58&source=winston×tamp=166964
7869281","span_id":"f80f3d4cb20e1a58","stack":"Error: Failed triggering hubspot email 9xxxxxxxxx4; response status is 400.\n at triggerHubspotSingleSendEmail (/Users/natashz/code/app/src/server/hubspot/index.ts:77:15)\n at processTicksAndRejections ……
At this point, without any further details, I had two options: (1) Add an elaborate logging of the error; or (2) debug our code and inspect it during execution. Instead, as the Helios instrumentation was in place, I could see that the printed log contained a link to the trace of the problematic flow.
When I opened it, I immediately saw the E2E flow and the erroneous operation, which was in fact the email sending. A quick look at the error details showed that the problem was with one of the parameters I passed to Hubspot’s API (the Bcc field was not passed in the appropriate way).
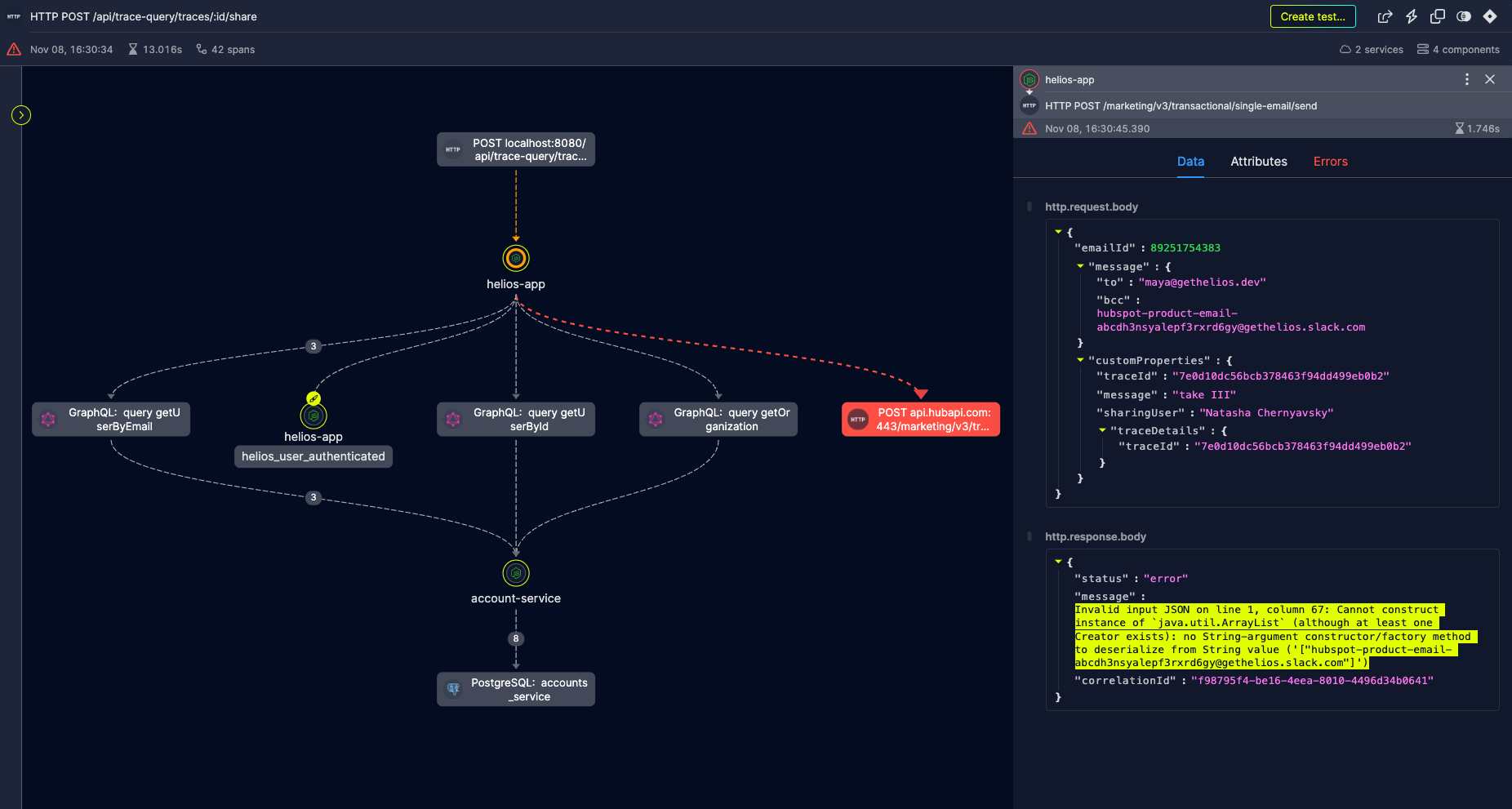
I quickly fixed it and the flow worked!
On a personal note, as a developer with more than 10 years of experience who has worked on dozens of third-party integrations in various roles, I can say that these tasks are not my favorite exactly because of the tiresome integration process. In the past few weeks alone, I integrated our product both with Hubspot and Jira and the overall time savings and smoother experience I had thanks to having Helios installed is definitely a game changer.
Conclusion
3rd party integrations can be frustrating. You need to learn its API, understand what is required to use it and where to integrate it into your service, and add the actual code. More often than not, documentation is limited and you’re left to learn as you develop via some trial and error, test your flow, and encounter errors on specific cases and inputs. In these cases, debugging is usually something you can’t avoid. With Helios, you can save the headache, as seen in our integration with Hubspot example, where we were able to ship our feature faster and more confidently.







