


In microservices architectures, apps are broken down into small, independent services that communicate with each other using APIs in a synchronous or asynchronous way.
Microservices carry many advantages, such as Increased flexibility and scalability (microservices can be scaled independently of each other, and APIs help to scale microservices by adding or removing instances of the service as needed), enhanced reliability (a failure in one doesn’t effect the other microservices as in monolith apps), better security, reduced development time and more.
However, microservices APIs are not problem free. API latency is a major obstacle in microservices, and it’s defined as the time it takes for an API to respond to a request. It is a critical factor in the performance of microservices applications.
In this aspect, it’s important to clarify the difference between latency and response time. These are two important metrics for measuring the performance of a system. They are often confused with each other, but they are actually two different things. Response time is the time it takes for a system to respond to a request. It includes the time it takes for the system to receive the request, process the request, and generate a response. Latency. On the other hand, is the time it takes for a message to travel from one point to another. It includes the time it takes for the message to travel through the network, as well as the time it takes for the system to receive and process the message. In short, it’s the remote response time. While both should be optimized, this article looks at latency.
Not surprisingly, latency is a big problem in microservices as microservices applications depend more on the communication between APIs: In a monolithic application, all of the code and data is located in a single process. This of course makes it easier to respond to requests quickly. In a microservices application, however, each service is its own individual process. This means that transaction events have to travel between processes, across different internal APIs which adds to the response time and may cause high latency. The problem worsens when scaling microservices – As the complexity of the service increases, there is a significant risk of increasing latency between microservices and application programming interfaces (APIs)
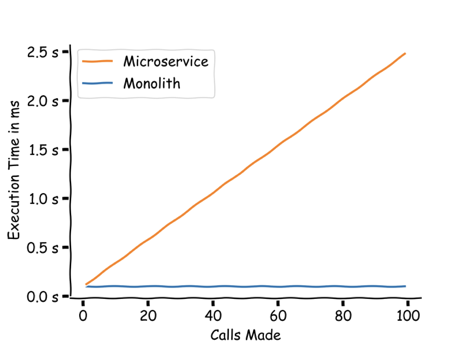
Why is it such a problem? Latency is a problem due to multiple reasons, such as slow response time for users, increased load on servers, reduced scalability, and more.
Moreover, debugging and troubleshooting API latency in microservices is challenging as tracking down the root cause can be a developer nightmare. After all, it can be caused by one single service, or it can be related to the communication between multiple services.
This article discusses the challenges of latency in microservices as well as some strategies, best practices and examples for reducing latency.
Internal APIs performance issues in microservices
There are a number of performance failures or issues that can occur with APIs in microservices architectures. Some of the most common issues include:
- Latency: As mentioned, latency is the time it takes for an API to respond to a request.
- HTTP errors: HTTP errors are a common type of error that can occur with APIs. HTTP errors are returned by the API when there is a problem with the request or the response. Some common examples include 404 Not Found, 500 Internal Server Error, and 403 Forbidden.
- Timeouts: Timeouts can occur when the latency is just too high and an API takes too long to respond to a request. Timeouts can be caused by a variety of factors, such as network congestion, overloaded servers, or errors in the code.
- Connection errors: Connection errors can occur when an API is unable to connect to the server. Connection errors can be caused by a variety of factors, such as network problems, server outages, or firewall rules.
- Invalid data: Invalid data can be sent to an API in a request. Invalid data can cause errors in the API, such as malformed requests or invalid parameters.
Deep dive into API latency in microservices
API latency in microservices is defined as the time it takes for the API to receive the request, process the request, and generate a response.
High API latency can occur due to multiple reasons, including:
- The number of microservices: The more microservices there are in an architecture, the more potential points of latency there are (therefore the problem is bigger when scaling microservices)
- The complexity of the microservices: The more complex the microservices are, the more time it takes for them to process requests.
- The network infrastructure: The quality of the network infrastructure can also impact latency.
- Network latency: The time it takes for a message to travel from one point to another can be a major factor in latency. This can be caused by factors such as distance, network congestion, and packet loss.
- Server latency: The time it takes for a server to process a request can also contribute to latency. This can be caused by factors such as server load, server resources, and the complexity of the request.
- Database latency: The time it takes for a database to return data can also be a factor in latency. This can be caused by factors such as database size, database load, and the complexity of the query.
- API design: The design of the API can also impact latency. For example, if the API is not designed to be efficient, it may require more round trips between the client and the server, which can increase latency.
- Caching: Not using caching can cause the API to fetch data from a slower storage medium, such as a database, every time a request is made.
- Load balancing: If load balancing is not implemented correctly, requests may be routed to overloaded servers.
- Service mesh: If a service mesh is not used, there will be no central point for managing and monitoring microservices.
- Observability: in microservices, If latency is not properly observed, it can lead to performance problems and outages.
Troubleshooting high API latency in microservices
Why do traditional monitoring methods fail?
Traditional monitoring methods fail to troubleshoot API latency in microservices architectures because they were not designed to handle the complexity of such architectures. They typically focus on monitoring individual servers and they alone can’t connect dependencies and performance across the entire customer journey through distributed architecture.
While monitoring is important, cloud-native application architectures require observability instead. As detailed in our article about API observability versus monitoring, API observability views much wider performance data compared to monitoring, in one place and in real-time, through observing individual services and the dependencies between them. It uses logs, metrics, and tracing to create a holistic strategy for monitoring.
Troubleshooting API latency effectively
To troubleshoot API latency in microservices architectures, it is important to use an observability solution that is designed for this type of architecture. These solutions typically provide features such as:
- Distributed tracing: Distributed tracing allows you to see the path that a request takes through a microservices architecture. This can help you to identify the source of latency problems.
- Service level objectives (SLOs): SLOs allow you to define acceptable levels of performance for your microservices. This can help you to identify and troubleshoot latency problems before they impact your users.
- Alerting: Alerting allows you to be notified when there are latency problems in your microservices architecture. This can help you to quickly identify and troubleshoot problems before they impact your users.
Debugging API latency with distributed tracing and OpenTelemtry
Distributed tracing is a way of tracking requests as they travel through a distributed system in order to identify and resolve performance bottlenecks and other problems. The most powerful tool to implement distributed tracing is OpenTelemetry, an OSS observability framework that collects and exports telemetry data from a variety of sources including apps, services, and infrastructure, through data instrumentation. OpenTelemetry can be used to collect data about the request, including the time it took to complete. This data can be used to identify performance bottlenecks and other issues. It’s a great tool as it’s vendor-neutral, and not tied to any specific vendor, technology, language or framework.
While no doubt that OTel is a life-changing tool, it has a few disadvantages that can be dealt with by using 3rd party tools that are based on this OSS. The main issues include implementation and maintenance complexity, lack of backend storage, lack of a visualization layer, and no actionable insights based on the data it collects.
Related:
OpenTelemetry tracing – Everything you need to know
E2E trace-based observability: Visualization and error insights
For effective troubleshooting of distributed systems and API latency in microservices, in particular, developers need an E2E observability solution that visualizes traces and spans, as well as collects granular error and performance-related data.
Helios is an OTel-based tool that helps Dev and Ops teams minimize MTTR in distributed applications. It helps developers install and maintain OpenTelemetry in no time, collect the full payload data, store telemetry data, visualize traces and spans, correlate them with logs and metrics, and enable error insights and alerts.
The tool provides a dashboard for each specific API in the catalog. This includes trends of the recent spans, duration distribution, HTTP response status code, errors and failures, and more. It lets developers filter APIs by errors with the full E2E context of each API call, enabling them to investigate what happened with the most relevant context and flow-drive mindset.
Related:
How we slashed detection and resolution time in half (Salt Security)
How Novacy Shortened Troubleshooting Time by 90%
An example: Root cause analysis of the increase in API latency
This example is also shared in this article: API observability: Leveraging OTel to improve developer experience.
In this example, the flow showing the visualization is composed of various endpoints and involves several services.
Here’s the first entry point of the visualization’s API in the app:
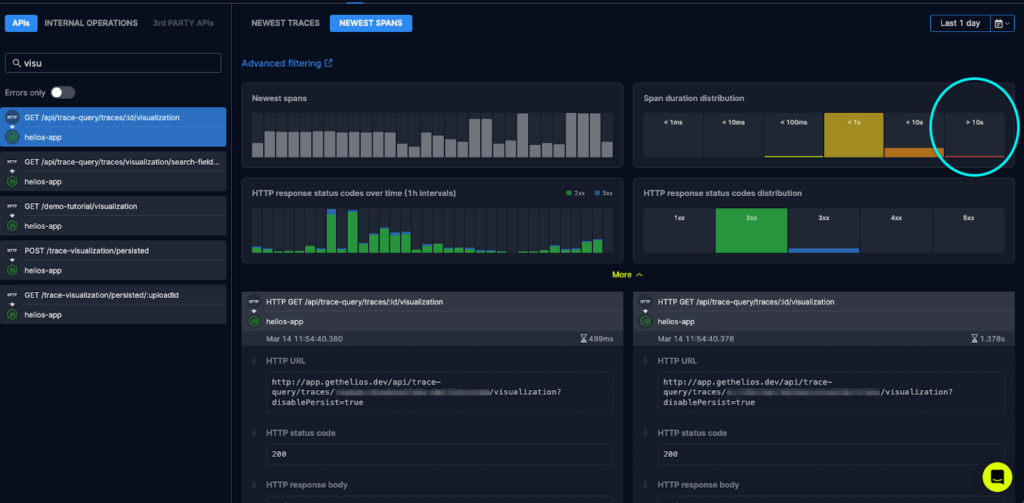
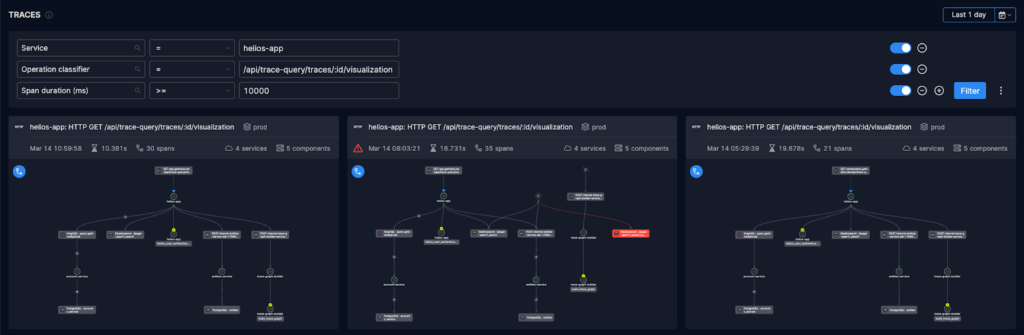
The investigation continues towards a minimal subset of traces, done by clicking on their visualizations and drilling down into the details (through the duration feature that pinpoints the bottlenecks):
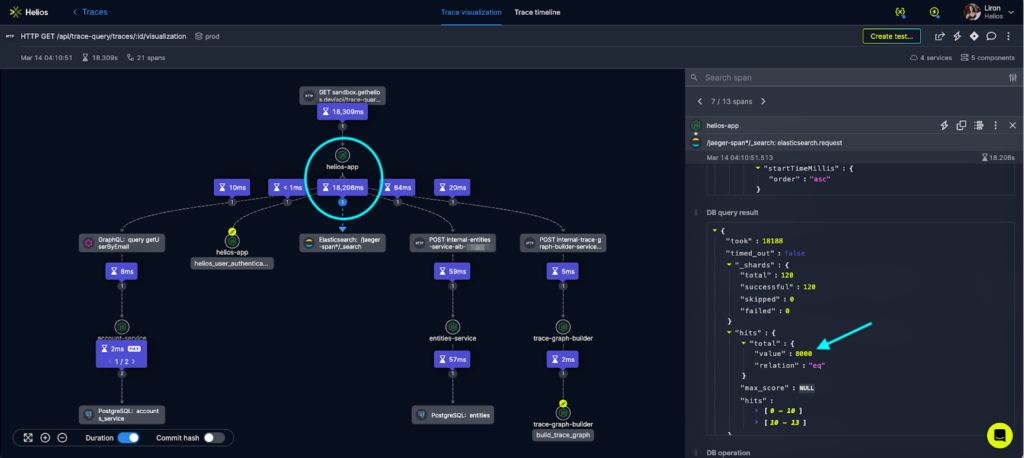
Investigating other spans can reveal a trend and see if the issue occurs in all other traces and that bottlenecks exist in all of them.
Related:
4 ways to reproduce issues in microservices
Conclusion
In conclusion, API latency poses a major challenge to microservice architectures. It can be caused by a variety of factors, including the number of microservices, their complexity, the network infrastructure, and the design of the API.
To troubleshoot API latency, it is important to use an observability solution that is specifically designed for microservices architectures. However, not all observability solutions provide all of the features that are needed to troubleshoot API latency in microservice architectures.
For example, some solutions do not collect data from all of the microservices in an architecture. Others do not provide trace-based visualization, which can make it difficult to identify the source of latency problems. Others still do not provide error insights and alerts, which can make it difficult to take action to resolve latency problems.
In order to make the most out of OpenTelemetry, you should use a solution that includes both visualization, granular data of the payloads, insights and error alerts.






