


Monitoring APIs through enhanced observability has gained traction with the popularity of microservices. Since microservice applications are built as independent and scalable modules, the number of microservices can grow dramatically as the application grows, increasing the complexity drastically. Since APIs work as the connective tissue between microservices, the number of APIs also grows in parallel. It makes API observability crucial as it helps developers identify issues early on and fix them before they escalate and reduces maintenance.
In this article, we will look at the pillars of API observability, what makes it different from API monitoring, and what tools can be used to implement API observability effectively.
What is API Observability? How is it different than monitoring?
Traditional monitoring focuses on tracking known unknowns. This means we already know what to track, but the metric value is unknown. For example, “requests per second” is a metric we know and track. But the metric value may be unknown.
However, API observability is focused on tracking issues that developers may not be aware of but can still significantly impact the performance of an API. These issues may include network latency, API version incompatibility, and other problems that may arise due to changes in the environment or unexpected user behavior. API observability allows you to respond to any queries on your API state and even replicate them.
Furthermore, API observability can be implemented for both external and internal APIs. External APIs are provided by external parties, such as customers or third-party developers, to consume services provided by the company. On the other hand, internal APIs are used within an organization to integrate different services and systems. In this article, we focus on internal APIs, which are the backbone of the microservices architecture. If you are interested in API observability in external APIs, follow this blog on applying observability to third-party integrations.
API observability vs API monitoring
Both API observability and monitoring are ways to track the status of your APIs and gain insights into how the APIs are performing, delivering value to clients, and what bottlenecks or issues they are facing. Although these two methods may sound similar at first, observability and monitoring follow two different approaches to monitoring the status of your APIs
API monitoring
API monitoring is the process of tracking and measuring the performance of an API over time to ensure that it is meeting its requirements and delivering the expected results. It involves collecting data about the API’s behavior, such as response times, error rates, and other key performance indicators (KPIs), and analyzing data to identify potential issues or areas for improvement.
However, API monitoring is observing the API as if you were an external user. So, when you incorporate metrics, you must anticipate potential issues and manually set up the necessary checks beforehand. As a result, API monitoring will only be able to assess the predetermined metrics, and any unknown problems may not be identified until they become more severe.
API observability
API observability enables developers to observe API comprehensively instead of relying on predetermined logs or monitoring. It provides a more detailed view of the API’s behavior by exploring characteristics and patterns that are not pre-defined or predetermined.
Furthermore, API observability enables developers to comprehensively observe the behavior of their APIs, identifying bottlenecks and troubleshooting issues quickly. This approach provides a holistic view of APIs and applications, improving the issue identification and resolution context. Additionally, API observability identifies unknown issues that may go unnoticed by traditional monitoring. For example, with API gateway observability, monitoring and analyzing traffic through the API gateway can also detect misconfigured routing rules or security threats. Ultimately, API observability offers a proactive approach to monitoring that improves performance and reduces downtime.
Pillars of API Observability
API observability is built on four key pillars:
- Functional test automation
- Performance management
- API security
- User analytics
Functional test automation
Functional test automation ensures that the API performs its intended function correctly. This includes understanding the API’s inputs and outputs and any dependencies on other microservices, databases, or external APIs. In the microservices architecture, functional test automation can be particularly challenging. Due to the distributed nature of microservices, it can be difficult to track down issues occurring across multiple services. However, with proper functional test automation, developers can gain visibility into how each service interacts with others and pinpoint issues more quickly.
Performance management
The performance management pillar of API observability focuses on tracking key metrics related to the API’s speed and responsiveness. This includes metrics such as requests per minute (RPM), status code distribution, and response duration. By tracking these metrics, developers can identify bottlenecks and performance issues and take steps to optimize the API’s performance.
Security
The security pillar identifies and addresses potential security vulnerabilities within the API. This includes tracking and analyzing access logs, detecting and responding to attacks, and implementing appropriate security measures.
User analytics
User analytics are crucial for businesses to understand their customer’s behavior, preferences, and frustrations. This data is vital for making informed business and product decisions. APIs are used to handle data across all application touchpoints, providing services to end-users. User analytics can help teams comprehend business dynamics, spot subtle patterns, and forecast future behavior. Gathering data through APIs and offering user analytics can help businesses expand quickly and make fewer errors.
In addition to these pillars, there are several specific metrics that developers should focus on when implementing API observability:
- API dependencies: API dependencies involve tracking the databases and other APIs (internal and external) that the API depends on. By monitoring API dependencies, developers can gain insight into potential bottlenecks or issues occurring elsewhere in the system.
- API stats: API stats include metrics such as RPM, status code distribution, and response duration. By tracking these metrics, developers can gain insight into how the API performs in real-time and identify performance issues before they become critical.
- API spec: It is essential to focus on API spec to ensure that the API remains consistent over time and in line with the definitions made by product/business teams. By monitoring API specs, developers can ensure that the API is meeting the needs of the business and delivering value to customers.
Advantages of API observability
API observability gives a holistic view of an application, which can help you identify issues in your application during the early stages and remedy those. Therefore having observability in your API has many advantages:
- Faster problem resolution: Developers can rapidly detect and solve problems, resulting in less downtime, reduced time to repair, and an enhanced user experience, thanks to enhanced visibility and understanding of the API’s behavior.
- Better collaboration: API observability allows developers to share insights and collaborate more effectively across teams, leading to improved communication and faster development cycles.
- Improved performance: By monitoring and analyzing API metrics, developers can identify and address performance issues, optimize API response times, and improve the overall efficiency of the system.
- Improved security: By monitoring API activity and detecting anomalies or suspicious behavior, API observability can help identify potential security threats early and prevent security breaches.
- Improved customer satisfaction: By providing a better user experience and faster problem resolution, API observability can help increase customer satisfaction and loyalty, leading to greater business success.
Use cases of API observability
With all the advantages API observability provides, businesses can use API telemetry to effectively support many use cases, including planning for API deprecation, finding API test coverage gaps, and identifying changes in API performance in production compared to its normal behavior.
API deprecation
API deprecation is a regular process, but planning for it can be challenging without enough insight into the API’s usage. API observability provides teams with data on the API’s requests per minute and the number of unique consumers, enabling them to make informed decisions about deprecation. The data can also be used to confirm that usage is declining as expected after a deprecation announcement.
Find API test coverage gaps
API testing ensures API functions as intended. But it may not cover all possible user interactions. API observability can help teams improve test coverage by providing insights into frequently used endpoints and methods, including their parameters. By capturing and validating these critical yet unforeseen user journeys, teams can expand their test suite and ensure greater reliability of their APIs.
Identify changes in API performance in production compared to its normal behavior
Teams often deploy their API to a separate staging environment before production deployment. This staging environment is intended to closely replicate the production environment, which allows the team to establish a baseline for expected API performance. By comparing production-level data to this baseline, teams can quickly detect and address any unexpected deviations as they occur.
Evaluating API observability tools
Observability is powered by telemetry data generated by APIs and other system components, including logs, metrics, and traces. Observability tools can help collect and aggregate these data and visualize them for better insights into API performance. As microservices can run on different technologies and patterns, finding an observability tool to monitor all services can be challenging. When evaluating observability tools, it is crucial to consider the features that allow for effective monitoring across all services.
Ease of deployment
A tool that is difficult to deploy or configure can be a significant barrier to adoption, as it can require significant resources and expertise to get up and run. On the other hand, a tool that is easy to deploy can help teams quickly gather valuable telemetry data from their API, allowing them to start making data-driven decisions and improving the user experience. Especially in a microservices environment with a large fleet of microservices, ease of deployment can be a key consideration.
Data collection granularity
The level of granularity in data collection is a crucial aspect of API observability tools. Such tools usually collect high-level data on API response time, request volume, and error rates. Still, some tools can also gather more detailed data, including headers and data related to user sessions. The appropriate level of granularity depends on several factors, such as the API complexity, the requirement of the organization, and the available resources. Collecting more granular data can provide deeper insights and detailed analysis of issues, but it also requires more resources and may pose data privacy and security risks. Therefore, organizations should carefully evaluate their needs and resources to determine the appropriate level of granularity for data collection.
Multi-language support
Multi-language support in an API observability tool refers to the ability of the tool to analyze and monitor APIs written in different programming languages. This is important since modern microservices-based applications are often built using multiple programming languages and frameworks, making it necessary for observability tools to support various languages. An API observability tool with multi-language support can provide insights into how APIs in different languages perform and interact. This also helps to identify performance issues, errors, and other anomalies that may arise due to language-specific behaviors.
Working with OpenAPI spec / AsyncAPI spec
Observability tools can leverage the OpenAPI and AsyncAPI specs to validate incoming API requests and outgoing API responses, ensuring compliance with the expected contract. Furthermore, they can also facilitate the process of debugging API issues. With the ability to see the expected behavior of an API according to the specification, developers can quickly identify where an API deviates from its contract and resolve issues accordingly.
Support for non-sync APIs
Support for non-sync APIs in an observability tool allows monitoring and analyzing APIs that use asynchronous or event-driven architectures. Unlike traditional observability tools designed for synchronous APIs, non-sync APIs make requests without immediate response, requiring event capture and analysis support. This capability is critical for applications that depend on non-sync APIs for real-time data processing or streaming.
Techniques such as distributed tracing, log aggregation, and correlation IDs are used to enable observability tools to follow request flows and events across different services, providing comprehensive insights into API performance and behavior.
API observability with OpenTelemetry and distributed tracing
OpenTelemetry (OTel) is a framework that offers a uniform open-source standard and a range of tools to collect and export logs, traces, and metrics from your cloud-native infrastructure and applications. You can use tools like Helios for easy implementation and to take observability to a whole new level. You will need such tools that provide actionable insight into the end-to-end application flow, adding visibility and error data to improve observability and reduce Mean Time To Repair (MTTR).
One of the main advantages of the tool is that it replaces the tedious implementation of OpenTelemetry and ongoing maintenance with a simple installation process. Users can view data across distributed systems and microservices and troubleshoot API fails allowing them to identify issues quickly and resolve them before they impact end-users, hence minimizing MTTR.
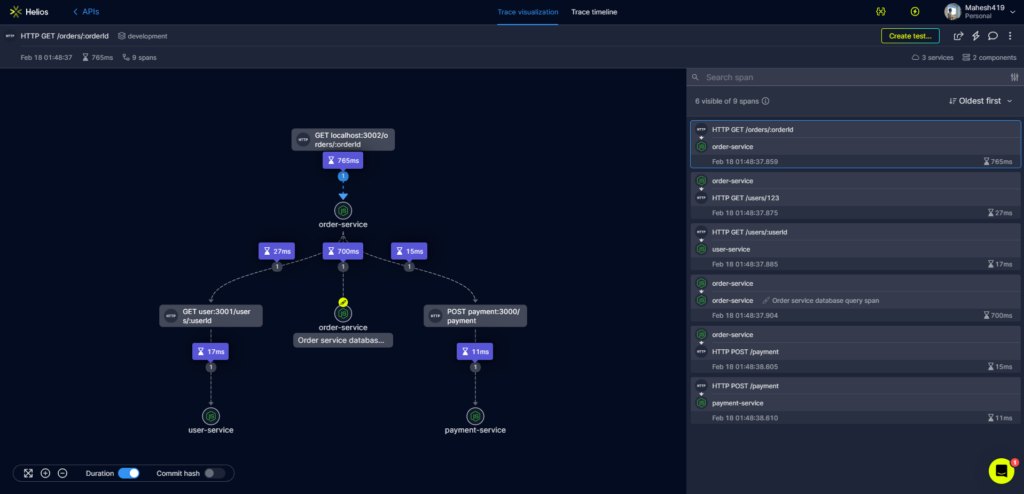
The above image depicts how Helios provides API telemetry (latency here) in a microservices application with the advanced trace visualization feature provided by Helios.
Additionally, Helios API observability offers features such as a dynamic API catalog, an API dashboard, and an auto-generated API spec for all HTTP interactions, along with an intuitive dashboard that allows users to visualize data on API performance and errors, enabling them to pinpoint issues and take corrective actions quickly. The dashboard includes features like trace view, service graph, and log analysis, which help users to diagnose issues quickly and improve overall API reliability.
Related: API observability: Leveraging OTel to improve developer experience
Conclusion
API observability is critical for modern organizations that rely on APIs to deliver their services. It allows teams to monitor, troubleshoot, and optimize their APIs in real-time, providing insight into their performance and behavior. OpenTelemetry provides a powerful platform for capturing and exporting the data necessary for API observability, supporting all major languages and frameworks.
Dev-first observability tools built on top of OpenTelemetry offer additional benefits such as visibility and error data, reducing MTTR, and shortening root cause analysis. With the increasing importance of APIs in today’s digital landscape, investing in API observability is essential for maintaining high-quality services and delivering a superior user experience.
Related: How we use trace-based alerts to reduce MTTR






