


A step-by-step guide for adding Prometheus-based metrics to your ECS Fargate application
Over the past few months, Helios has experienced rapid growth resulting in our user base increasing, our services multiplying, and our system ingesting more data. Like all tech companies that need to scale, we wanted to avoid our performance becoming sluggish over time. As an engineer on the team, I was tasked with putting application metrics in place to measure the performance of our services and identify where bottlenecks in our data ingestion exist so that we could improve our ingestion throughout and handle scale. At Helios, we run our services in AWS ECS Fargate since it gives us a sufficient level of container management abstraction, thereby reducing DevOps overhead for our engineering team. Little did I know that configuring custom Fargate application metrics in CloudWatch using Prometheus was not an easy task due to lack of documentation around this use case.
In this article I share the steps I took to configure these application metrics in hopes that other devs in similar situations find it valuable.
Measuring the throughput of our data ingestion
It all started with a very basic requirement any developer needs in their day-to-day work: adding a metric to troubleshoot/assess a flow in the system. Specifically, I wanted to measure the throughput of the services in our ingestion pipeline, so I sought to expose application metrics via Prometheus and make them visible in Grafana. While this might seem like a pretty trivial thing to do, it turns out it was pretty complex in our architecture. Our services run in Fargate and we use CloudWatch for monitoring our services performance. At first, I wasted a great deal of time trying to understand how to configure Prometheus – I was surprised because I couldn’t find much documentation/tutorials on it online.
As a first step, I needed to expose metrics from the services in our ingestion pipeline to Prometheus. This step varies between languages and has plenty of “how-tos” on the web, so it was straightforward. Our applications are written in Typescript and I used promClient. But then I needed to figure out how to see my application metrics in CloudWatch and then in Grafana. This was the “fun” part and I describe my steps below.
- The baseline I relied on was this AWS article, which I referred to for installing the Prometheus-collector AWS Fargate task. Look for ‘View Prometheus metrics in CloudWatch’ in the article and follow the steps for installing the collector.
- After the Prometheus task is deployed, you need to make sure it has access to your application in order to scrape the metrics. Add an inbound rule in your application security group to accept connection from the Prometheus task.
- In order for the collector to discover your app’s Fargate task, you need to add a docker label. Edit your app task definition and add a docker label (in our case we added ‘
PROM_METRICS=true’). Then, update the service to run with the latest task definition.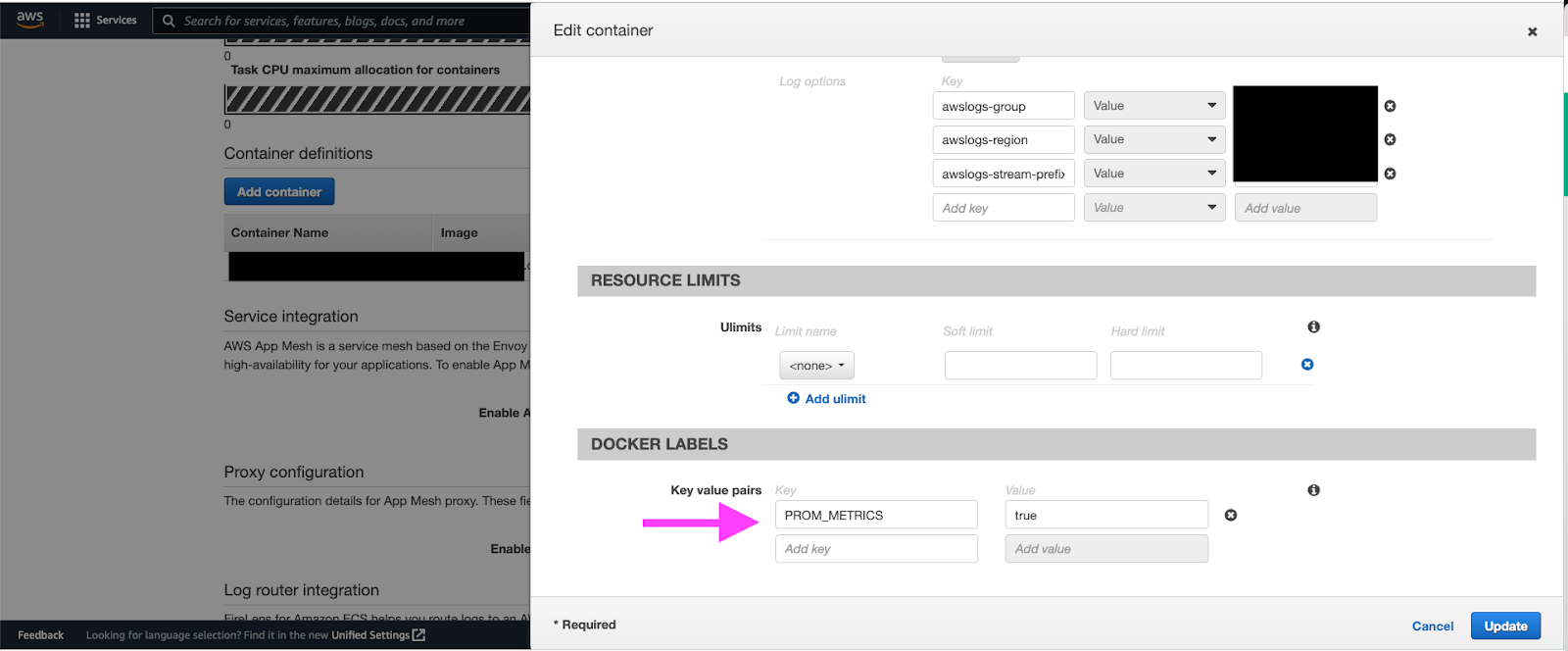
Docker label configuration for Fargate services - You’ll need to add two JSON configuration files to your AWS Parameter Store (in the above article there are examples of these JSONs):
- The first one is for the Prometheus task configuration.
Example:global: scrape_interval: 1m scrape_timeout: 10s scrape_configs: - job_name: <JOB_NAME_FOR_CONFIGURATION> sample_limit: 10000 file_sd_configs: - files: [ "<PATH_TO_CONFIG_YAML>" ]
- The second one is the service’s metrics path+port to allow the Prometheus collector to discover the service and the metric configuration itself.
Example:{ "agent": { "debug": true }, "logs": { "metrics_collected": { "prometheus": { "prometheus_config_path": "env:PROMETHEUS_CONFIG_CONTENT", "ecs_service_discovery": { "sd_frequency": "1m", "sd_result_file": "/tmp/cwagent_ecs_auto_sd.yaml", "docker_label": { }, "task_definition_list": [ { "sd_job_name": "<CHOOSE_JOB_NAME>", "sd_metrics_ports": "<APP_PROMETHEUS_METRICS_PORT>", "sd_task_definition_arn_pattern": ".*:task-definition/<APP_TASK_DEFINITION>*", "sd_metrics_path": "<APP_PROMETHEUS_METRICS_PATH>" } ] }, "emf_processor": { "metric_declaration_dedup": true, "metric_declaration": [ { "source_labels": [ "<DOCKER_LABEL_ADDED_TO_YOUR_APP>" ], "label_matcher": "^<DOCKER_LABEL_VALUE_ADDED_TO_YOUR_APP>$", "dimensions": [ [ "ClusterName", "TaskDefinitionFamily", <MORE_METRICS_LABELS> ] ], "metric_selectors": [ "^<METRIC_NAME>" ] } ] } } }, "force_flush_interval": 5 } }
- The first one is for the Prometheus task configuration.
- Then, restart the Prometheus collector task to use the updated JSON configuration.
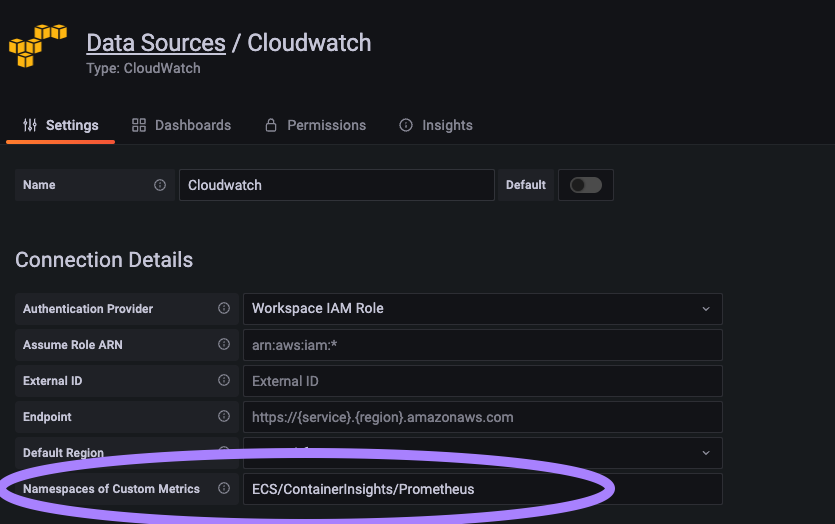
- After the service is up you’ll be able to see your metric under CloudWatch > All metrics > ECS/ContainerInsights/Prometheus.
- To view your metrics in Grafana, assuming you already configured CloudWatch<>Grafana integration, you’ll simply need to add a custom metric path in the ‘Settings‘ page in Grafana:
* * * *
The above is my experience adding Prometheus-based metrics to ECS Fargate applications. I relied on these metrics at Helios as a way to measure our services performance so we could improve data ingestion throughout our product and better handle scale. Next time you come across this scenario, I hope you’ll turn to this article as a guide! If you have any questions, feel free to reach out to me at liron@gethelios.dev.
Related: How we combined OpenTelemetry traces with Prometheus metrics to build a powerful alerting mechanism







