


What do you do when things break in production?
Debugging microservices isn’t a walk in the park. Microservices are designed to be loosely coupled, which makes them more scalable and resilient, but also more difficult to debug. When a problem occurs in a microservices app, it can be difficult to track down the source of the problem. When the problem is in production, the clock is ticking and you have to resolve the issues fast.
Unlike traditional monolith apps, where issues can break the entire app, microservices apps are based on isolated services (in theory) that can work independently. In other words, if there’s a bug, it may not affect the entire app. However, this isolation of microservices increases the probability of unexpected problems that occur in production.
When deploying code in production, performance issues can be unpredictable and difficult to reproduce. It’s extremely hard to predict what will happen in a production environment when processing millions of requests on distributed servers. Code or database issues can cause multiple failures.
Traditional debugging methods include APM solutions, log analyzers and more. Microservices-specific debugging practices were developed to compensate for the gaps of traditional tools.
In this article, we will discuss the complexities of debugging microservices apps in production and will look into best practices and recommendations for developers of distributed systems.
Related: How Novacy Shortened Troubleshooting Time by 90%
Debugging cloud-native apps—General overview
Microservices vs. monolith
Briefly put, microservices are much more difficult to debug than monoliths because they are distributed systems, which means that they are made up of multiple independent services that communicate with each other. Generally speaking, debugging microservices requires a more holistic approach than debugging monoliths. This means that you need to be able to understand how the different services are interacting with each other, and you need to be able to observe and track the flow of requests through the system.
Microservices-specific debugging challenges
Debugging microservices is challenging due to multiple reasons:
-
- Complexity due to the distributed nature: Microservices are basically multiple independent services that communicate with each other over the network. Each failure has its own context of communication flow, out of many possibilities. This makes it extremely difficult to track down the source of a problem, reproduce it, and check its pattern.
-
- Lack of visibility: In many cases, there is limited visibility into the inner workings of microservices. Event flows create a huge challenge in understanding how the overall process is actually carried out, as various event notifications hold that knowledge.
-
- Heterogeneity: Microservices used in the same app can be written in different programming languages and use different frameworks, and be deployed in different environments. Developers need to understand the different programming languages, frameworks, and environments that are used by microservices.
“Microservices hell” – Source
Observability versus monitoring: Debugging approaches
The difference between observability vs. monitoring focuses on whether data pulled from the system is predetermined or not. Monitoring is an approach to collecting and analyzing predetermined data, while observability aggregates all granular data produced by the system, usually by using instrumentation.
Usually, monitoring tools will be able to reveal only anomalies that can be anticipated by the team, and simply present data, observability measures the input and output across microservices, programs, servers, and databases.
Unlike traditional monitoring, observability offers actionable insights into the health of the apps, and proactively detects anomalies.
Due to the nature of microservices and the unique challenges described above, monitoring approaches can’t be sufficient for efficient debugging, and E2E observability is essential.
Why logs aren’t enough
Logs limitations are specifically challenging when it comes to microservices environments:
-
- Root cause limitations: Logs from different microservices may be scattered across different systems, and they don’t provide enough data about the communication between microservices
-
- Lack of context: Traditional logs often lack context, making it difficult to understand the flow of requests through a distributed system.
-
- Volume: Traditional logs can reach overwhelming volumes, making it difficult to find the information you need when you are troubleshooting a problem. Also, too many logs mean that the code will be too heavy, and the maintenance will be tedious. Finally, what’s too much and what’s too little, when it comes to logs?
-
- Time-consuming: Traditional logging isn’t automatic and it’s not error-free. You can spend your youth adding logs and still miss on the needed data when something goes wrong.
Many solutions out there offer optimization to log limitations by following multiple approaches and best practices, but debugging microservices requires another approach: end-2-end.
Trace-based observability to the rescue
Trace-based observability is a technique for monitoring and debugging microservices that is becoming the standard these days. It’s based on tracing the flow of requests through a distributed system by recording the time, source, and destination of each request as well as the granular data of each payload. A trace typically consists of a sequence of events that occurred during a transaction.
This information can then be used to identify the root cause of a problem, understand the behavior of a distributed system, and dramatically improve the efficiency of debugging.
The main benefits include improved visibility of requests flow (trace-backed visualization), automation (unlike logs, traces are automatic as they are based on auto-instrumentation) reduced troubleshooting time (due to visual representation of the flow requests), improved performance (by helping developers identify bottlenecks and other performance issues) and improving developer experience (Have you tried debugging microservices apps using traditional logging?)
Trace-based observability is built on 3 pillars: traces, spans, and tags. They all work together to provide a comprehensive view of the flow of requests through a distributed system. Traces provide the overall context, spans provide the details of individual operations, and tags provide additional granular information that is needed to fasten the root cause analysis.
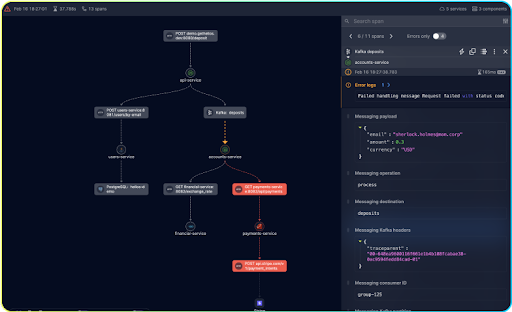
Distributed tracing visualization with granular data. source: Helios
The role of OpenTelemetry
Today, trace-based observability is enabled mainly through OpenTelemetry, an open-source observability framework that provides a unified set of APIs and SDKs for collecting, exporting, and analyzing telemetry data. This data can include traces, logs, and metrics, and can be collected from a variety of sources, including microservices, databases, and cloud infrastructure.
OpenTelemetry is designed to be vendor-neutral, which makes it a valuable tool for organizations that want to be able to collect and analyze telemetry data from a variety of sources using a single framework.
Learn more about OpenTelemetry
Debugging microservices in production – Challenges and best practices
We all know the drill… The app works fine in the local environment, but then things break in production…
Developers can spend hours trying to understand why something only occurs in production, having to deal with the type of bugs they hate most: production bugs.
As if debugging, in general, isn’t challenging enough, production debugging can be even more challenging. Why is that? Here are a couple of reasons:
-
- Latency: Latency can be difficult to troubleshoot in production, as it can be caused by a variety of factors, including network congestion, database queries, and slow microservices. In a development environment, you can usually reproduce the problem by running the code locally. However, in production, you may not be able to reproduce the problem, which can make it difficult to track down the source of the latency.
-
- Scale: Microservices applications can be scaled to handle large amounts of traffic. This can make debugging difficult, as you may need to reproduce the problem in a scaled environment in order to track down the source of the problem. In a development environment, you can usually scale the application by locally running multiple instances of the code. However, in production, you may not have the ability to scale the application, which can make it difficult to troubleshoot problems.
-
- Load: The load on an application in production can be much higher than the load on the application in development. This can make it difficult to reproduce problems, as the problem may only occur under certain load conditions.
-
- Data: The data that is used by an application in production may be different from the data that is used by the application in development. This can make it difficult to track down the source of a problem, as the problem may be caused by a difference in the data.
-
- Environment: The environment in which microservices are deployed in production can be very different from the environment in which they are developed. This can make it difficult to debug problems, as the code may behave differently in the production environment. For example, the production environment may have different hardware, software, and network configurations than the development environment.
-
- Time pressure: When a problem occurs in production, there is often limited time to fix the problem. Stress and timeline constraints can make it difficult to debug problems, as you may not be able to take the necessary steps to track down the source of the problem.
-
- Risk: Debugging apps in a production environment can potentially disrupt the current users of the running application, can slow down the performance of the application or even crash the app altogether, or require a restart. We’re honestly not sure which is worse.

So why debug in production at all?
Having said all that, debugging in production can still be valuable as it allows finding and fixing issues while the app is still running, without needing to reproduce issues, which is an unbearable task in its own merit. When a failure occurs in production, reproducing the issue locally is often too complex of a process that can take days or weeks. It may not even be possible at all!
Lastly, observing production environments enables you to optimize the quality of the apps by identifying and resolving problems that didn’t occur in development.
Production debugging: Approaches and best practices
Logging is (still) the most common way of debugging microservices in production, but as written above, its limitations in microservices are prominent. Moreover, it will sometimes demand that you write additional logs for troubleshooting, and then you must redeploy and restart the application, just to extract the additional needed data.
You will need a tool that lets you analyze all the data that can shed light on the error, in production, without interfering with the end-user experience. Successful debugging in production means not breaking anything, not slowing down any applications, and basically not causing any ruckus.
Here are a few advanced best practices that specifically address production debugging in microservices:
-
- As long as you are using logging, use a consistent format. This will make it easier to correlate logs from different microservices. For example, you can use a standard format such as JSON or XML.
-
- Use a centralized cloud-based logging system. This will make it easier to search and filter logs.
-
- Use a tool that supports microservices. This will allow you to walk through the code of your microservices. There are a number of distributed tracing tools that support microservices, such as Jaeger or Helios.
-
- Use a distributed tracing tool that is tailored to microservices and is based on auto instrumentation. This will allow you to track the flow of requests through your microservices.
-
- Add observability capabilities to your monitoring stack.
-
- Use a staging environment and, if possible, create one that is identical to your production environment. This will allow you to test your debugging strategies before you deploy them to production.
-
- Use a canary release. A canary release is a technique where you deploy a new version of your application to a small subset of users. This allows you to test the new version of your application in production before you deploy it to all users.
-
- Use a rollback strategy. In case you do introduce a new problem, have a rollback strategy in place so you can quickly roll back to the previous version of your application if the problem is significant and production MTTR can’t be short enough.
Insist on tracing-visualization and granular E2E payload data
While there are quite a few tools that offer distributed tracing, not many offer trace visualization and very few collect the entire payload data that is essential. Helios does have these capabilities.
Trace visualization is important because it allows developers to see a graphic representation of the flow of requests through their microservices.
All granular payload data is needed to provide context for the problem. For example, if you are seeing a latency issue, the payload data can help you to identify the specific spans that cause the latency and narrow down the specific APIs.
Specifically, you will need to be able to use a tool that can help you with auto generating of API catalogs, filtering traces based on multiple options, getting alerts based on error insights, understanding sync and async flows, event streams and queues, traversing complex flows to identify bottlenecks and errors, generating a code to trigger a specific flow in one click, editing trigger configuration on the spot, saving, sharing and reusing triggers, and more.
But, not less importantly, a distributed tracing tool that’s based on auto-instrumentation makes adding logs to production environments for debugging purposes redundant.
Real-life example
Say a microservices application is used to process orders. One day, the team starts receiving reports from users saying that their orders are not being processed. The team investigates the problem and learns that the requests are getting stuck in the “processing” microservice.
When using logging, the team had to manually inspect the logs of each microservice to see where the problem was occurring—a time-consuming and error-prone process. Moreover, the team had to code new logs for missing data.
However, when the team started using distributed tracing and instrumenting the code, all payload data was extracted automatically, and trace visualization showed exactly where the requests were getting stuck in the processing.
The granular payload data offered the full context of what data is being processed between the “processing” and “database”, and the team could see that the “processing” microservice was passing a large amount of data to the “database” microservice.
In this example, the root cause of the problem was that the “database” microservice was not able to handle the large amount of data that was being passed to it. A database upgrade was therefore applied.
This error did not happen in a development environment; it started in production.
The team estimated that the same problem would carry an MTTR of 3-5 hours when using logging only, but could be reduced to 0.5-1 hours if distributed tracing was involved.
Related: Debugging microservices – A trace visualization worth a thousand words
Conclusion
Debugging microservices in production is challenging due to multiple reasons.
Traditional logging is not enough to debug microservices effectively. Trace-based observability is essential as it provides a more holistic view of the flow of requests through the system, with contextual data, and the ability to show traces in a visual manner.
We presented quite a few best practices and concrete tips for efficient microservices debugging in production.
Low MTTR of production debugging and a friendly experience are dependent on a tool that not only enables distributed tracing, but can also offer trace-based visualization, and all granular payload data including error insights. Check how it looks in our sandbox.






