


Scaling the deployment, in order to meet demand or extend capabilities, is a known challenge in many fields, but it’s particularly pertinent when scaling microservices. This article looks at the challenges of scaling microservices and examines best practices to overcome them while maintaining app quality, dev efficiency, and a good developer experience.
What is microservices scalability?
Microservices scalability refers to the ability of a microservices architecture to handle increasing demand without performance degradation. There are two main approaches to scaling microservices: vertical scaling and horizontal scaling, based on the Scale Cube.
The Scale Cube
Let’s start with some theory. The Scale Cube is a model that has been around for quite some time now. It indicates methods (or approaches) by which technology platforms may be scaled to meet increasing levels of demand on the system in question.
The three dimensions of the Scale Cube are:
- Vertical scaling (X-axis): This involves increasing the resources available to a single microservice, such as memory, CPU, or storage. This can be a quick and easy way to achieve scalability, but it can also be expensive.
- Horizontal scaling (Y-axis): This involves adding more instances of a microservice to the system. This can be more scalable than vertical scaling, but can also be more complex to implement.
- Partitioning (Z-axis): This involves dividing the data or functionality of a microservice into smaller parts. This can be done for a variety of reasons, such as to improve performance, scalability, or security.
For example, if your app is CPU-intensive, you may want to use vertical scaling to increase the resources available to the microservices. If it’s I/O-intensive, horizontal scaling helps by adding more instances of the microservices.
Naturally, the Y-axis is the one relevant to the microservices paradigm.
Why is scalability critical?
In short, without scalability, microservices applications quickly become overloaded and unresponsive. This can lead to poor user experience or system failure.
When scalability becomes a problem, we can see quite a few critical errors, for instance:
- A microservice that is responsible for handling user logins becomes overloaded. This can be due to a sudden spike in traffic to the application, but can also occur if the microservice is not properly scaled. The result: users are unable to log in, or the performance is very slow.
- A microservice for storing user data becomes unavailable as it was not scaled properly. In this scenario, users can’t access their data.
- A microservice for communicating with another microservice becomes unresponsive due to being overloaded. This can lead to errors and performance issues.
Specific Challenges of scaling microservices
One of the biggest challenges in microservices relates to scalability issues. As demonstrated above, scaling microservices can’t be the same practice as scaling a monolith app. While it may sound obvious, in practice successful scaling is not easily achieved due to multiple challenges:
Microservices too tightly coupled
Microservices are designed to be loosely coupled, which means that they should not be overly co-dependent. This makes them easier to scale independently, as you can scale each microservice without affecting the others. However, if microservices are too tightly coupled in the first place, it can be difficult to scale them independently. This is because if one microservice becomes overloaded, it can affect the other microservices that depend on it. Also, tightly coupled microservices increase the chances of errors (one affects the other) and increase complexity.
Coupling microservices too tightly can happen due to lack of experience, technical debt (features added over the time, with no one investing in decoupling actions), time constraints, etc.
Implementing wrong scaling strategies
As written above, scaling can be done using different strategies. The optimal one depends on many factors including the way the app is built, the budget for scaling, the amount of traffic it is built to deal with. When the wrong scaling strategy is implemented, the results can lead to high costs of resources, performance issues and added complexity.
Incompatible load-balancing
Load balancing is used to distribute traffic across multiple instances of a microservice, in order to prevent any single microservice from becoming overloaded and unresponsive. When the load balancing solution is not compatible with the microservices architecture, it can lead to performance problems (e.g., the load balancer is dividing the traffic evenly instead of based on each request’s handling time), latency, and inconsistency (splitting the traffic between the microservices, but not in a consistent way, which leads to returning different results for the same request). Another issue can be around the single source for failure (load balancing decisions being made from a central node and in case of the central node crashing).
Improperly configured caching systems
Caching helps to reduce the number of requests that need to be made to the database, which benefits both performance and scalability. However, when caching systems are not properly configured, they can actually be the reason for scalability challenges. For example, if a caching system is not sized correctly, it can become overloaded and unresponsive. Also, if data isn’t properly synchronized between the cache and the DB, inconsistent results are bound to be generated.
Performance issues blindness
Scalability challenges can be related to performance issues that are hard to identify. Lack of proper observability and monitoring prevents the developers from identifying the problem until it becomes severe, and makes them struggle with the root cause analysis. The same challenge is related to inappropriate metrics or Inadequate logging.
Data consistency failures
Scalability challenges can be closely related to data consistency issues. Microservices are designed to be loosely coupled, which means that they should not be overly co-dependent. This makes them easier to scale independently, but also more susceptible to data consistency failures. For example, if one microservice updates a piece of data, but another microservice does not receive the update, this can lead to data inconsistency. Tightly coupling microservices is a challenge, but loosely coupled microservices can also be a threat to data consistency.
Additionally, microservices typically manage their own state. This means that each microservice is responsible for keeping track of its own data. If one microservice updates a piece of data, but another microservice does not update its state accordingly, this can lead to data inconsistency.
Lastly, microservices communicate with each other using APIs. If these APIs are not designed properly, this can lead to data consistency failures.
All of these issues are more likely to occur in scaling microservices applications. First, as microservices applications scale, they become more complex, which makes it more difficult to design and implement data consistency mechanisms. Second, as microservices applications scale, they become more and more distributed across services. This can make it more difficult to ensure that data is synchronized.
Increased latency
There are a few reasons why latency can increase in scaling microservices applications. First, as mentioned in point 6, when microservices applications scale they become more distributed. This makes it harder for requests to travel between microservices, which can increase latency. Second, as microservices applications scale, they become more complex, and optimizing performance becomes challenging.
Communication failures
Once again, as microservices applications scale they become more distributed. When microservices are spread across multiple servers and networks, it becomes harder for them to communicate with each other. Failures can be related to network congestion, latency and fault tolerance.
Resource contention failures
As microservices applications scale, they also require more resources. This can lead to contention for resources, such as CPU, memory, and network bandwidth.
Lack of automation
When there are no processes or tools in place to automatically scale microservices up or down in response to changes in load, it can lead to a number of problems, including performance degradation, unnecessary costs (If a microservice is not scaled down in response to decreased load, it continues to consume resources unnecessarily) and outages (when a failing microservice isn’t automatically replaced).
Observability failures
A large microservices architecture can involve hundreds or even thousands of microservices. This can make it difficult to track the behavior of all of the microservices and to identify any problems that may occur. Also, loosely coupled microservices may lead to observability failures; microservices may not be directly connected to each other, which can make it difficult to track the interactions between them. Observability failures occur when the monitoring system isn’t built for microservices observability, like when it isn’t based on instrumenting all needed data to get the full picture of what’s going on.
Scaling microservices best practices
Independent scalability is one of the main advantages of microservices, but it’s nonetheless challenging. In monolithic architecture, straightforward scaling approaches such as load balancing are relatively easy to implement. After all, the app is a single unit and one only needs to add more resources to fit the volume. There’s no independent scaling of each component, separately. That’s not the way it works in microservices.
For an effective scaling of microservices-based apps, engineers must track performance and efficiency goals. While microservices design includes known best practices such as loose (but not too loose) coupling, API-first design, continuous integration and deployment, fault tolerance, EDA (event-driven architecture), security, specific monitoring capabilities and more, some best practices are especially important for microservices scalability:
- Use a container orchestration platform. Container orchestration platforms such as Kubernetes can help to automate the scaling of microservices by ensuring that microservices are scaled up or down as needed.
- Use a service mesh. A service mesh helps engineering teams run microservices at scale by offering a more flexible release process (for example, support for canary deployments, A/B testing, and blue/green deployments) availability, and resilience (for example, set up retries, failovers, circuit breakers, and fault injection).
- Use load balancers. This will help you distribute traffic across multiple microservices and prevent any single microservice from becoming overloaded. Popular load balancers include HAProxy, Nginx, Amazon Elastic Load Balancing (ELB), Azure Load Balancer, and Google Cloud Load Balancing.
- Use distributed tracing. A dedicated monitoring and observability tool that enables distributed tracing and is based on code instrumentation will track the flows between microservices, quickly identify issues and direct you to the root cause fast. Tools include Jaeger, Zipkin, New Relic, and Helios (that’s us, more info is shared below).
- Use decoupled architecture. Decoupled microservices can be scaled independently of each other.
- Start small and scale up as needed. It is not always necessary to scale microservices to their maximum capacity; it is often better to start small and scale up as needed, to avoid over-provisioning resources and to save costs.
- Use autoscalers. Autoscalers can help to automatically scale microservices up or down as needed. This ensures that microservices are scaled efficiently and that costs are kept under control. For example, the Kubernetes Horizontal Pod Autoscaler (HPA) can be used to automatically scale pods up or down based on the CPU usage of the pods.
- Have a contingency plan. Know ahead what steps to take in case a microservice fails. Use tooling that will minimize MTTR – Read more on: How we use trace-based alerts to reduce MTTR
Trace-based observability and visualization
While log-based observability is a traditional approach to monitoring and troubleshooting software, as microservices architectures become more complex, log-based observability becomes less efficient. This is because logs don’t collect all needed event-based data. They are typically stored in a centralized location, which can make it difficult to correlate logs from different microservices. Furthermore, they can be voluminous, which makes it difficult to find relevant information, especially when it comes to the flows between microservices.
Trace-based observability, on the other hand, uses a technique called distributed tracing to track requests as they flow through a microservices architecture. Distributed tracing allows you to see the entire request lifecycle, from the initial request to the final response. This information can be used to identify performance bottlenecks, troubleshoot errors, and improve the overall performance of the application. Distributed tracing is based on code instrumentation is the process of adding code to a microservice to collect telemetry data. code instrumentation can be done manually or automatically.
One of the most popular tools for distributed tracing is OpenTelemetry’s open-source software. It enables the extraction of telemetry data through instrumentation. However, to make OTel effective there’s a need to collect and host the data, analyze it, visualize traces, and provoke alerts as well. Helios is a tool that’s based on OTel but also includes E2E distributed tracing observability, allowing developers to easily implement OpenTelemety, visualize traces and troubleshoot issues as quickly as possible, lowering MTTR by 90%
Detection (Automatic alerts):
When running diagnostics, additional data is provided. The screen below shows an example for diagnosis (not related to the alert above, in this case):
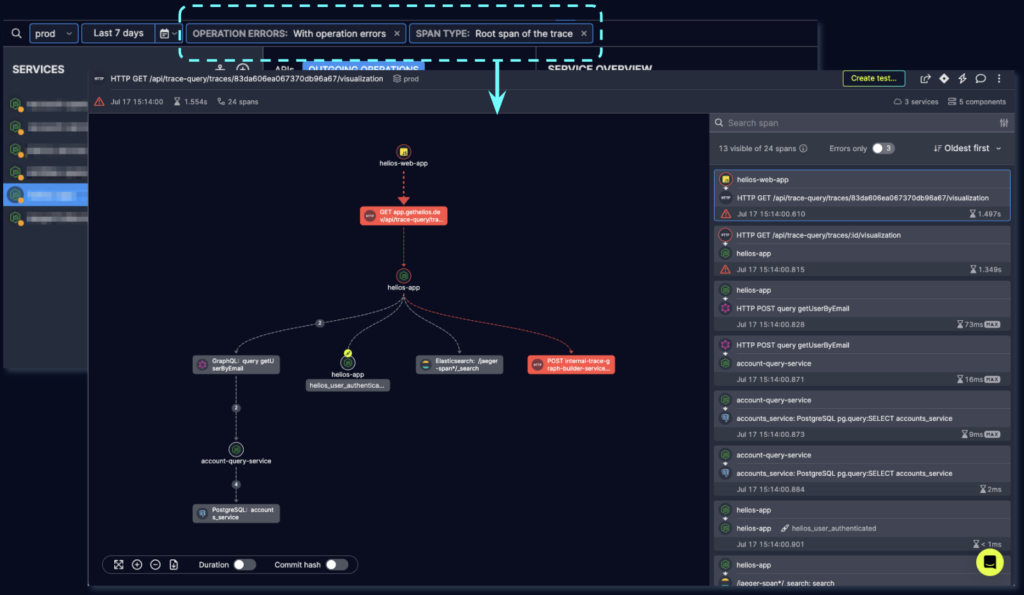
Troubleshooting (root cause analysis) – an example for tace based visualization with granular data (not related to the above):
Related real-life examples:
How Novacy Shortened Troubleshooting Time by 90%
How Salt Security slashed detection and resolution time in half
Example: When scaling goes wrong: troubleshooting strategy
Symptoms: The application is slow and unresponsive. Users are reporting that they are getting timeout errors when they try to access the application.
Telemetry data: The metrics show that the CPU usage is high and the memory usage is high. The distributed traces show that the requests are taking a long time to complete.
Distributed tracing: The distributed traces show that the requests are spending a lot of time in the microservice that handles the database. The microservice that handles user authentication is also taking a long time to respond.
Analysis: The analysis of the telemetry data and the distributed traces shows that the database and the user authentication microservices are overloaded.
Troubleshooting: Troubleshooting would involve fixing the root cause of the database overload and the user authentication microservice overload. This could involve updating the database schema, adding more capacity to the database, optimizing the database queries, updating the user authentication microservice code, or adding more capacity to the user authentication microservice.
To reproduce the issue, you could try to increase the load on the application by running more concurrent requests. You could also try to access the application from different geographic locations.
To troubleshoot the issue in production, you could use the following steps:
- Collect telemetry data from the application
- Analyze the telemetry data to identify the microservices that are failing
- Use distributed tracing to track requests as they flow through the microservices architecture
- Identify the root cause of the failure in each microservice
- Fix the root cause of the failure in each microservice
- Redeploy the microservices
- Monitor the application to ensure that the failure does not recur
With logging, it would take a long time to identify the microservices that are failing because the logs would be scattered across different microservices. It would also be difficult to correlate the logs from different microservices. Additionally, the logs would only provide a limited view of the application’s behavior, which would make it difficult to identify the root cause of the failure.
With distributed tracing, the microservices that are failing can be identified quickly because distributed tracing can track requests as they flow through the microservices architecture. Additionally, distributed tracing can provide a more granular view of the application’s behavior, which can help with identifying the root cause of the failure more quickly.
For example, let’s say that the application is slow and unresponsive. Using logging, it might take hours or even days to identify the microservices that are failing and to understand why they are failing. However, using distributed tracing, the microservices that are failing can be identified in minutes or even seconds. Additionally, distributed tracing can provide information about the specific requests that are failing, which can help to identify the root cause of the failure more quickly.
As a result, the MTTR would be significantly lower if distributed tracing was used instead of logging.
In the image below – Trace based visualization with granular data (of the span and related errors):
Conclusion
Scaling microservices is a complex and challenging task, but it is essential for ensuring that microservices applications can handle increasing demand. There are a number of best practices that can be followed to improve the scalability of microservices applications. Implementing monitoring and observability solutions based on distributed tracing is specifically important, as they as they are used to to track the performance of microservices, identify problems, and quickly resolve scalability issues through instant root cause analysis.






