


The Dark Side of Microservices
But let’s back up a bit, and see how we even got here. Microservices and serverless have become increasingly popular in the last decade since they allow engineering teams to be more agile and flexible and take advantage of the benefits of the cloud. As more companies are born into the cloud, and legacy enterprises digitally transform, architectures are becoming more distributed and engineering teams are moving faster than ever.
This software architectural revolution has had profound business results for companies and has enabled engineers to develop amazing capabilities. But it has also had some side effects that haven’t been addressed yet. Namely, the lack of visibility (or observability, if you prefer) for engineers that prevents pushing code from their local machine to any environment, with confidence.
True, we have logs and some of us have traces. But raise your hand if you’ve found a truly efficient way to add logs and traces, search through them without feeling you’re looking for a needle in a haystack and find the answer without feeling overwhelmed with data. We’ve all felt it. The tools were there, but they weren’t doing what we wanted them to do. We were spending our time looking for errors instead of fixing them, not to mention feature development.
The result? Developers are still lacking confidence to make changes, velocity is negatively impacted and changes that are made – are not of high enough quality.
One of the reasons we’re all facing these challenges is that while cloud computing and infrastructure monitoring tools have evolved with the cloud, day-to-day tools for development haven’t evolved at the same pace. Today, there are plenty of great tools out there for production monitoring, container monitoring, and production troubleshooting. But shifting left into production readiness is still a blue ocean.
Replacing Distributed Tracing Time with Feature Development Time – with Open Source
One of the most inspiring aspects of being a developer is the ability to take part in the developer community, especially in open source projects. There are a lot of lines of code to be written if we’re going to achieve our global goals for technological advancement. So we need to be able to collaborate on code, instead of each of us starting from scratch.
That’s why we set out to find a solution that was open-source-based. That solution was OpenTelemetry, an open-source collection of APIs, SDKs, and tools for instrumentation and data collection. With OpenTelemetry, developers can get telemetry data in the form of logs, traces, and metrics, and then push the data to their analysis tools. This enables them to (a) collect the data and (b) gain initial visibility into the state of the services they’ve been working on.
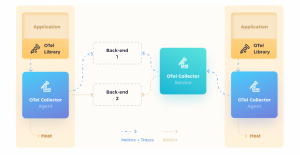
OpenTelemetry is a huge enabler for the standardization of data collection. The largest software companies, like Google and Microsoft, have been contributing to it, and it’s growing popularity among developer teams is bringing teams closer to achieving data observability.
What’s Next after OpenTelemetry?
But is OpenTelemetry enough for enabling microservices production readiness? Should we pack up our belongings and go found a different startup? Not quite.
First of all, there’s still a lot of work to be done for making OpenTelemetry accessible and useful for developers. Until now, most of the OpenTelemetry focus has been on DevOps and SRE use cases in production. Developers and pre-production environments have not been addressed properly, and the potential is huge.
This is why we’re investing a lot in shifting left OpenTelemetry. We are continuously contributing as a team in both Python and Node.js. We want to increase OpenTelemetry among developers, make it accessible in any R&D organization and help make it a part of all phases of the SDLC.
But more importantly, we have a vision for the next step after OpenTelemetry; after it becomes a commodity for data collection. While OpenTelemetry enables gathering data, there’s still a question of making it accessible to developers. Today, it’s still hard for developers to understand the data, for example, which actions triggered which results, which service correlations exist, and what’s the impact of a code change on architecture components. In other words, they’re missing actionable insights they can implement during development. This is where Helios comes in.
Introducing Helios – Making Distributed Tracing Actionable for You
We built Helios to help developers do more with the data they already have and to make data accessible. Helios takes instrumentation data, from OpenTelemetry or other sources, and provides comprehensive visibility into the architecture components as well as actionable insights that actively assist with feature development, debugging, and troubleshooting.
For example, our users can use Helios to reproduce service states, identify system inefficiencies and understand trace flows.
This provides developers with the confidence to make continuous changes in their code. Data is not just available, it is accessible, at all times. This consistency creates a sense of developer confidence that enables production-readiness in any environment – local, testing, development, stage, and yes, also production.
And since we know testing is another pain developers have, Helios also automatically creates tests for developers.
The result is an end-to-end platform that provides engineering insurance to make changes in code. From alerts about the consequences of code changes on other services to automated test creation to visibility into architecture – Helios utilizes distributed tracing hands it to developers, ready for them to quickly fix errors and get back to product development.
Where do we go from here?
As we start 2022, we’re making Helios accessible and inviting beta users to try out the product, provide feedback and take part in making Helios the most developer-friendly tool for production readiness. We’re excited and honored to invite you to join our journey.
Get started with Helios here.






